Filter Function Plugin Library
JavaScript plugins that enable custom filter functions for gitStream. To learn how to use these examples, read our guide on how to use gitStream plugins.
askAI
The AskAI plugin allows gitStream workflows to interact with external AI services, enabling advanced automation capabilities such as code analysis, test case generation, and PR summarization. This plugin requires a valid API token for the AI service, which must be securely provided as an environment variable.
Security note
The AskAI plugin integrates with an external AI model and requires your API token for authorization. Ensure you provide a valid token through the env.OPEN_AI_TOKEN parameter or similar configuration. This may also incur API costs.
When using the AskAI plugin, the provided context and prompt will be shared with the configured AI service. Ensure that no sensitive or proprietary information is included unless your organization's policies permit it.
Returns: Object - Returns the AI-generated response based on the provided context and prompt. License: MIT
| Param | Type | Description |
|---|---|---|
| context | Object | The context that needs to be sent to the AI model for analysis. |
| role | string | Free text. If not empty, Defines the role or persona for the AI to adopt while generating the response. |
| prompt | string | The specific request or question you want the AI to respond to, after the context has been provided. |
| token | Object | The token to the AI model |
Example
{{ source | askAI("QA tester", "Based on the given context, search for new functions without tests and suggest the tests to add. If all functions are covered completely, return 'no tests to suggest.'", env.OPEN_AI_TOKEN) }}
Plugin Code: askAI
/**
* @module askAI
* @description A gitStream plugin to interact with AI models. Currently works with `ChatGPR-4o-mini`.
* @param {Object} context - The context that will be attached to the prompt .
* @param {string} role - Role instructions for the conversation.
* @param {string} prompt - The prompt string.
* @param {Object} token - The token to the AI model.
* @returns {Object} Returns the response from the AI model.
* @example {{ branch | generateDescription(pr, repo, source) }}
* @license MIT
* */
const MAX_TOKENS = 4096;
const OPEN_AI_ENDPOINT = 'https://api.openai.com/v1/chat/completions';
const LOCK_FILES = [
'package-lock.json',
'yarn.lock',
'npm-shrinkwrap.json',
'Pipfile.lock',
'poetry.lock',
'conda-lock.yml',
'Gemfile.lock',
'composer.lock',
'packages.lock.json',
'project.assets.json',
'pom.xml',
'Cargo.lock',
'mix.lock',
'pubspec.lock',
'go.sum',
'stack.yaml.lock',
'vcpkg.json',
'conan.lock',
'ivy.xml',
'project.clj',
'Podfile.lock',
'Cartfile.resolved',
'flake.lock',
'pnpm-lock.yaml',
'uv.lock'
];
const EXCLUDE_EXPRESSIONS_LIST = [
'.*\\.(ini|csv|xls|xlsx|xlr|doc|docx|txt|pps|ppt|pptx|dot|dotx|log|tar|rtf|dat|ipynb|po|profile|object|obj|dxf|twb|bcsymbolmap|tfstate|pdf|rbi|pem|crt|svg|png|jpeg|jpg|ttf)$',
'.*(package-lock|packages\\.lock|package)\\.json$',
'.*(yarn|gemfile|podfile|cargo|composer|pipfile|gopkg)\\.lock$',
'.*gradle\\.lockfile$',
'.*lock\\.sbt$',
'.*dist/.*\\.js',
'.*public/assets/.*\\.js',
'.*ci\\.yml$'
];
const IGNORE_FILES_REGEX_LIST = [
...LOCK_FILES.map(f => f.replace('.', '\\.')),
...EXCLUDE_EXPRESSIONS_LIST
];
const EXCLUDE_PATTERN = new RegExp(IGNORE_FILES_REGEX_LIST.join('|'));
/**
* @description Check if a file should be excluded from the context like "package-lock.json"
* @param {*} fileObject
* @returns returns true if the file should be excluded
*/
const shouldExcludeFile = fileObject => {
const shouldExludeByName = EXCLUDE_PATTERN.test(fileObject.original_file);
const shouldExludeBySize = (fileObject.diff?.split(' ').length ?? 0) > 1000;
return shouldExludeByName || shouldExludeBySize;
};
/**
* @description Check if a file should be included in the context
* @param {*} fileObject
* @returns returns true if the file should be included
*/
const shouldIncludeFile = fileObject => {
return !shouldExcludeFile(fileObject);
};
const buildContextForGPT = context => {
if (Array.isArray(context)) {
return context.filter(element =>
typeof element !== 'object' ? true : context.filter(shouldIncludeFile)
);
}
if (context?.diff?.files) {
const files = context.diff.files.filter(shouldIncludeFile);
return files;
}
return context;
};
const askAI = async (context, role, prompt, token, callback) => {
const formattedContext = buildContextForGPT(context);
if (!formattedContext?.length) {
const message = `There are no context files to analyze.\nAll ${context?.diff?.files?.length} files were excluded by pattern or size.`;
console.log(message);
return callback(null, message);
}
const response = await fetch(OPEN_AI_ENDPOINT, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${token}`
},
body: JSON.stringify({
model: 'gpt-4o-2024-08-06',
messages: [
{
role: 'system',
content: `You are a ${role}. Answer only to the request, without any introductory or conclusion text.`
},
{
role: 'user',
content: JSON.stringify(formattedContext)
},
{ role: 'user', content: prompt }
],
max_tokens: MAX_TOKENS
})
});
const data = await response.json();
if (data?.error?.message) {
console.error(data.error.message);
return callback(null, data.error.message);
}
const suggestion =
data.choices?.[0]?.message?.content ??
'context was too big for api, try with smaller context object';
return callback(null, suggestion);
};
module.exports = {
async: true,
filter: askAI
};
gitStream CM Example: askAI
triggers:
exclude:
branch:
- r/dependabot/
automations:
generate_pr_desc_on_new_pr:
on:
- pr_created
if:
- true
run:
- action: add-comment@v1
args:
comment: |
{{ source | askAI("Experienced developer", "Summarize in simple terms the changes in this PR using bullet points.", env.OPEN_AI_TOKEN) }}
generate_pr_desc_on_ask_ai_label:
on:
- label_added
if:
- {{ pr.labels | match(term="/ask-ai qa") | some }}
run:
- action: add-comment@v1
args:
comment: |
{{ source | askAI("qa tester", "Based on the given context, search for new functions without tests and suggest the tests to add. If all functions are covered completely, return 'no tests to suggest.'", env.OPEN_AI_TOKEN) }}
checklist
Automatically check PRs against a checklist of conditions. This is useful if you want to ensure that PRs meet certain criteria before they can be merged.
Returns: string - Returns a formatted GitHub comment with a checklist of conditions that the PR meets.
License: MIT
| Param | Type | Description |
|---|---|---|
| Input | string | A blank string (no input variable is required) |
| branch | object | The branch context variable. |
| files | object | The files context variable. |
| pr | object | The pr context variable. |
| repo | object | The repo context variable. |
| env | object | The env context variable. |
| source | object | The source context variable. |
Example
With this plugin, you can easily customize the checklist using the object in the JavaScript code. To add a new check to the list, just add a new object with a descriptive title for your own benefit, a label that'll get posted in the comment, and the condition that, if true, would cause the entry in the checklist to be checked off.
Plugin Code: checklist
/**
* @module checklist
* @description Automatically check PRs against a checklist of conditions.
* This is useful if you want to ensure that PRs meet certain criteria before they can be merged.
* @param {string} Input - A blank string (no input variable is required)
* @param {object} branch - The branch context variable.
* @param {object} files - The files context variable.
* @param {object} pr - The pr context variable.
* @param {object} repo - The repo context variable.
* @param {object} env - The env context variable.
* @param {object} source - The source context variable.
* @returns {string} Returns a formatted GitHub comment with a checklist of conditions that the PR meets.
* @example
* - action: add-comment@v1
args:
comment: {{ "" | checklist(branch, files, pr, repo, env, source) }}
* @license MIT
**/
const checklistFilter = async (empty, branch, files, pr, repo, env, source, callback) => { // made sync temporarily
const checks = [
{
title: "low-risk",
label: "The PR is a low-risk change",
// our sample definition of a low-risk change is a docs-only PR from designated docs writers
condition: files.every(file => /docs\//.test(file)) && pr.author_teams.includes("tech-writers")
},
{
title: "has-jira",
label: "The PR has a Jira reference in the title",
condition: /\b[A-Za-z]+-\d+\b/.test(pr.title)
},
{
title: "updates-tests",
label: "The PR includes updates to tests",
condition: files.some(file => /[^a-zA-Z0-9](spec|test|tests)[^a-zA-Z0-9]/.test(file))
},
{
title: "includes-docs",
label: "The PR includes changes to the documentation",
condition: files.some(file => /docs\//.test(file))
},
{
title: "first-time",
label: "The PR author is a first-time contributor",
condition: repo.author_age < 1 && repo.age > 0 // if the PR author made their first contirbution on the current day
},
{
title: "requires-opsec",
label: "The PR doesn't expose any secrets",
condition: source.diff.files
.map(file => file.new_content)
.every(file_content =>
[
"MY_SECRET_ENVIRONMENT_VARIABLE"
].every(env_var => !file_content.includes(env_var))
// nothing added to any file during this comment contains any of the secret environment variables in this array
)
}
];
const comment = await Promise.resolve(checks
.map(check => `- [${check.condition ? "x" : " "}] ${check.label}`)
.join("\n"));
return callback(
null,
JSON.stringify(comment)
);
};
module.exports = {
async: true,
filter: checklistFilter
}
gitStream CM Example: checklist
# -*- mode: yaml -*-
manifest:
version: 1.0
automations:
checklist:
if:
- true
run:
- action: add-comment@v1
args:
comment: {{ "" | checklist(branch, files, pr, repo, env, source) }}
compareMultiSemver
Processes a list of pairs of semantic version numbers and determines the most significant change among them.
Returns: string - It returns a string of either: 'major' if any pair has a major version increment. 'minor' if no pair has a major version increment but has a minor version increment. 'patch' if no pair has major or minor version increments but has a patch version increment. 'downgrade' if no pairs have a higher version. 'equal' if all pairs are equal. 'error' if the comparison is abnormal or cannot be determined.
License: MIT
| Param | Type | Default | Description |
|---|---|---|---|
| listOfPairs | Array.<Array> | An array of version pairs, where each pair is an array of two semantic version strings. |
Example
Plugin Code: compareMultiSemver
/**
* @module compareMultiSemver
* @description Processes a list of pairs of semantic version numbers and determines the most significant change among them.
* Each pair consists of two versions to be compared.
* @param {string[][]} listOfPairs - An array of version pairs, where each pair is an array of two semantic version strings.
* @returns {string} It returns a string of either:
* 'major' if any pair has a major version increment.
* 'minor' if no pair has a major version increment but has a minor version increment.
* 'patch' if no pair has major or minor version increments but has a patch version increment.
* 'downgrade' if no pairs have a higher version.
* 'equal' if all pairs are equal.
* 'error' if the comparison is abnormal or cannot be determined.
* @example {{ [["1.2.3", "1.2.1"], ["1.3.1", "1.2.3"]] | compareMultiSemver == "minor" }}
* @license MIT
*/
const compareSemver = require('../compareSemver/index.js');
module.exports = (listOfPairs) => {
const priority = {
'major': 3,
'minor': 2,
'patch': 1,
'downgrade': 0,
'equal': -1,
'error': -2
};
let mostSignificantChange = 'equal';
listOfPairs.forEach(pair => {
const result = compareSemver(pair);
if (priority[result] > priority[mostSignificantChange]) {
mostSignificantChange = result;
}
});
return mostSignificantChange;
}
const compareMultiSemver = require('./index.js');
console.assert(compareMultiSemver([["1.2.3", "1.2.1"], ["1.3.1", "1.2.3"]]) === 'minor', `compareSemver([["1.2.3", "1.2.1"], ["1.3.1", "1.2.3"]]) == 'minor'`);
console.assert(compareMultiSemver([["1.2.3", "0.2.1"], ["1.3.1", "1.2.3"]]) === 'major', `compareMultiSemver([["1.2.3", "0.2.1"], ["1.3.1", "1.2.3"]]) === 'major'`);
console.assert(compareMultiSemver([["2.2.3", "0.2.1"], ["1.3.1", "1.2.3"]]) === 'major', `compareMultiSemver([["2.2.3", "0.2.1"], ["1.3.1", "1.2.3"]]) === 'major'`);
console.assert(compareMultiSemver([["1.2.3", "1.2.1"], ["1.2.4", "1.2.3"]]) === 'patch', `compareMultiSemver([["1.2.3", "1.2.1"], ["1.2.4", "1.2.3"]]) === 'patch'`);
gitStream CM Example: compareMultiSemver
manifest:
version: 1.0
automations:
bump_minor:
if:
- {{ bump == 'minor' }}
run:
- action: approve@v1
- action: add-comment@v1
args:
comment: |
bot `minor` version bumps are approved automatically.
bump_patch:
if:
- {{ bump == 'patch' }}
run:
- action: approve@v1
- action: merge@v1
- action: add-comment@v1
args:
comment: |
bot `patch` version bumps are approved and merged automatically.
bump: {{ [["1.2.3", "1.2.1"], ["1.3.1", "1.2.3"]] | compareMultiSemver }}
compareSemver
compareSemver → checkSemver
This plugin is now supported by a native filter function checkSemver. The native implementation provides better performance and doesn't require plugin installation.
extractDependabotVersionBump
extractDependabotVersionBump → checkDependabot
This plugin is now supported by a native filter function checkDependabot. The native implementation provides better performance and doesn't require plugin installation.
extractRenovateVersionBump
Extract version bump information from Renovate PRs description
Returns: Array.<string> - V1 (to) and V2 (from) License: MIT
| Param | Type | Description |
|---|---|---|
| description | string | the PR description |
Example
Plugin Code: extractRenovateVersionBump
/**
* @module extractRenovateVersionBump
* @description Extract version bump information from Renovate PRs description
* @param {string} description - the PR description
* @returns {string[]} V1 (to) and V2 (from)
* @example {{ pr.description | extractRenovateVersionBump | compareMultiSemver }}
* @license MIT
**/
module.exports = (desc) => {
const results = [];
if (desc && desc !== '""' && desc !== "''") {
const regex =
/\[[\\]*`([\d\.]+[A-Za-zαß]*)[\\]*` -> [\\]*`([\d\.]+[A-Za-zαß]*)[\\]*`\]/g;
let matches = null;
do {
matches = regex.exec(desc);
if (matches?.length === 3) {
let [_, from, to] = matches;
// remove trailing dot on to
if (to.at(-1) === ".") {
to = to.slice(0, -1);
}
results.push([to, from]);
}
} while (matches !== null);
}
return results;
}
gitStream CM Example: extractRenovateVersionBump
manifest:
version: 1.0
automations:
bump_minor:
if:
- {{ bump == 'minor' }}
- {{ branch.name | includes(term="renovate") }}
- {{ branch.author | includes(term="renovate") }}
run:
- action: approve@v1
- action: add-comment@v1
args:
comment: |
Renovate `minor` version bumps are approved automatically.
bump_patch:
if:
- {{ bump == 'patch' }}
- {{ branch.name | includes(term="renovate") }}
- {{ branch.author | includes(term="renovate") }}
run:
- action: approve@v1
- action: merge@v1
- action: add-comment@v1
args:
comment: |
Renovate `patch` version bumps are approved and merged automatically.
bump: {{ pr.description | extractRenovateVersionBump | compareMultiSemver }}
extractSnykVersionBump
Extract version bump information from Snyk PRs description
Returns: Array.<string> - V1 (to) and V2 (from) License: MIT
| Param | Type | Description |
|---|---|---|
| description | string | the PR description |
Example
Plugin Code: extractSnykVersionBump
/**
* @module extractSnykVersionBump
* @description Extract version bump information from Snyk PRs description
* @param {string} description - the PR description
* @returns {string[]} V1 (to) and V2 (from)
* @example {{ pr.description | extractSnykVersionBump | checkSemver }}
* @license MIT
**/
module.exports = (desc) => {
if (desc && desc !== '""' && desc !== "''" ) {
const matches = /Upgrade.*from ([\d\.]+[A-Za-zαß]*) to ([\d\.]+[A-Za-zαß]*)/.exec(desc);
if (matches && matches.length == 3) {
var [_, from, to] = matches;
// remove trailing dot on to
if (to[to.length - 1] === ".") {
to = to.slice(0, -1);
}
return [to, from];
}
}
return null;
}
gitStream CM Example: extractSnykVersionBump
manifest:
version: 1.0
automations:
bump_minor:
if:
- {{ bump == 'minor' }}
- {{ branch.name | includes(term="snyk-update"") }}
- {{ branch.author | includes(term="snyk-update"") }}
run:
- action: approve@v1
- action: add-comment@v1
args:
comment: |
Snyk `minor` version bumps are approved automatically.
bump_patch:
if:
- {{ bump == 'patch' }}
- {{ branch.name | includes(term="snyk-update"") }}
- {{ branch.author | includes(term="snyk-update"") }}
run:
- action: approve@v1
- action: merge@v1
- action: add-comment@v1
args:
comment: |
Snyk `patch` version bumps are approved and merged automatically.
bump: {{ pr.description | extractSnykVersionBump | checkSemver }}
extractOrcaFindings
Extract security issues information from Orca PR reviews
Returns: Object - Findings Findings.infrastructure_as_code: { count: null, priority: '' }, Findings.vulnerabilities: { count: null, priority: '' }, Findings.secrets: { count: null, priority: '' },
License: MIT
| Param | Type | Description |
|---|---|---|
| PR | Object | the gitStream's PR context variable |
Example
Usage example, that adds lables based on Orca Secuirty findings.
Plugin Code: extractOrcaFindings
/**
* @module extractOrcaFindings
* @description Extract security issues information from Orca PR reviews
* @param {Object} pr - the gitStream's PR context variable
* @returns {Object} Findings
* Findings.infrastructure_as_code: { count: null, priority: '' },
* Findings.vulnerabilities: { count: null, priority: '' },
* Findings.secrets: { count: null, priority: '' },
* @example {{ pr | extractOrcaFindings }}
* @license MIT
**/
function getOrcaPropertyRating(lines, lineIdentifierRegex, findingsCellIndex) {
const matches = lines.filter(x => x.match(lineIdentifierRegex));
const [firstMatch] = matches;
const cells = firstMatch.split('|');
const [_, high, medium, low, info] = /"High"> ([\d]+).*"Medium"> ([\d]+).*"Low"> ([\d]+).*"Info"> ([\d]+)/
.exec(cells[findingsCellIndex])
.map(x => parseInt(x));
return {high, medium, low, info};
}
module.exports = (pr) => {
let orcaObject = {
infrastructure_as_code: { count: null, priority: '' },
vulnerabilities: { count: null, priority: '' },
secrets: { count: null, priority: '' },
};
// Orca comments are added as PR review
const orcaComment = pr.reviews.filter(x => x.commenter.includes('orca-security'));
if (orcaComment.length) {
const orcaCommentArray = orcaComment[orcaComment.length - 1].content.split('\n');
var priority = getOrcaPropertyRating(orcaCommentArray, /Infrastructure as Code/, 3);
orcaObject.infrastructure_as_code = {
count: priority.high + priority.medium + priority.low + priority.info,
priority,
};
var priority = getOrcaPropertyRating(orcaCommentArray, /Vulnerabilities/, 3);
orcaObject.vulnerabilities = {
count: priority.high + priority.medium + priority.low + priority.info,
priority,
};
var priority = getOrcaPropertyRating(orcaCommentArray, /Secrets/, 3);
orcaObject.secrets = {
count: priority.high + priority.medium + priority.low + priority.info,
priority,
};
}
return JSON.stringify(orcaObject);
}
gitStream CM Example: extractOrcaFindings
# -*- mode: yaml -*-
manifest:
version: 1.0
automations:
{% for item in reports %}
label_orca_{{ item.name }}:
if:
- {{ item.count > 0 }}
run:
- action: add-label@v1
args:
label: 'orca:{{ item.name }}'
{% endfor %}
orca: {{ pr | extractOrcaFindings }}
reports:
- name: introduced-cves
count: {{ orca.vulnerabilities.count }}
- name: iac-misconfigurations
count: {{ orca.infrastructure_as_code.count }}
- name: exposed-secrets
count: {{ orca.secrets.count }}
colors:
red: 'b60205'
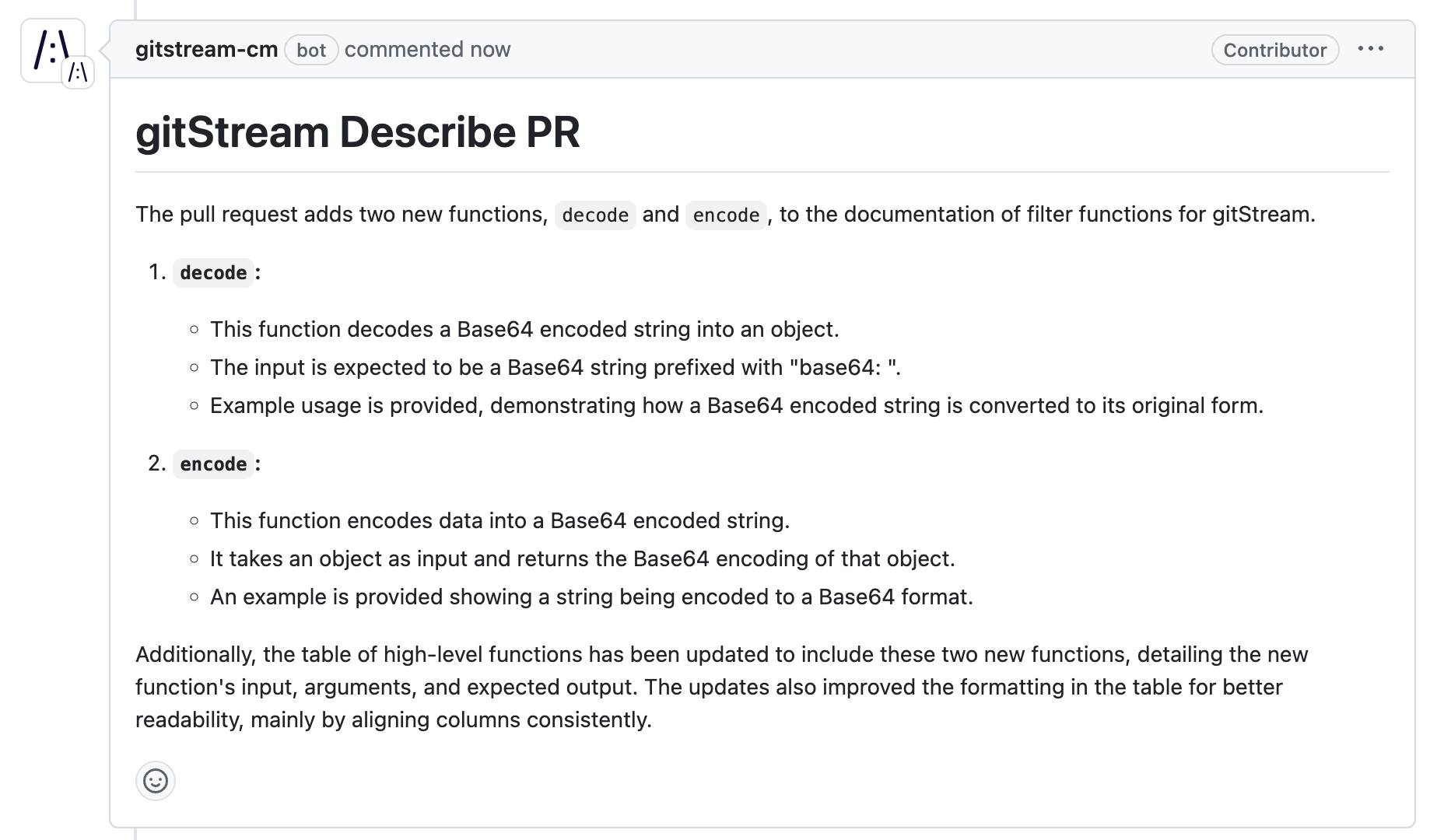
generateDescription
A gitStream plugin to auto-generate pull request descriptions based on commit messages and other criteria.
Returns: Object - Returns the generated PR description. License: MIT
| Param | Type | Description |
|---|---|---|
| branch | Object | The current branch object. |
| pr | Object | The pull request object. |
| repo | Object | The repository object. |
| source | Object | The source object containing diff information. |
| callback | function | The callback function. |
Example
Plugin Code: generateDescription
/**
* @module generateDescription
* @description A gitStream plugin to auto-generate pull request descriptions based on commit messages and other criteria.
* @param {Object} branch - The current branch object.
* @param {Object} pr - The pull request object.
* @param {Object} repo - The repository object.
* @param {Object} source - The source object containing diff information.
* @param {function} callback - The callback function.
* @returns {Object} Returns the generated PR description.
* @example {{ branch | generateDescription(pr, repo, source) }}
* @license MIT
**/
// Parse commit messages
function parseCommitMessages(messages) {
const commitTypes = {
feat: [],
fix: [],
chore: [],
docs: [],
style: [],
refactor: [],
perf: [],
test: [],
build: [],
ci: [],
other: [],
};
messages
.filter((message) => !message.includes("Merge branch"))
.forEach((message) => {
const match = message.match(
/^(feat|fix|chore|docs|style|refactor|perf|test|build|ci):/,
);
if (match) {
commitTypes[match[1]].push(message.replace(`${match[1]}:`, "").trim());
} else {
commitTypes.other.push(message);
}
});
return commitTypes;
}
// Format commit section
function formatCommitSection(type, commits) {
return commits.length
? `> - **${type}:**\n${commits.map((msg) => `> - ${msg}`).join("\n")}\n`
: "";
}
function containsNewTests(files) {
const testPattern = /(test_|spec_|__tests__|_test|_tests|\.test|\.spec)/i;
const testDirectoryPattern = /[\\/]?(tests|test|__tests__)[\\/]/i;
const testKeywords = /describe\(|it\(|test\(|expect\(/i; // Common test keywords for JavaScript
for (const file of files) {
const { new_file, diff, new_content } = file;
// Check if the filename indicates it's a test file
if (testPattern.test(new_file) || testDirectoryPattern.test(new_file)) {
return true;
}
// Check if the diff or new content contains test-related code
if (testKeywords.test(diff) || testKeywords.test(new_content)) {
return true;
}
}
return false;
}
function extractUserAdditions(description) {
const match = description.match(
/<!--- user additions start --->([\s\S]*?)<!--- user additions end --->/,
);
return match ? match[1].trim() : description.trim();
}
// Generate PR description
async function generateDescription(branch, pr, repo, source, callback) {
if (process.env[__filename]) {
return callback(null, process.env[__filename]);
}
const commitTypes = parseCommitMessages(branch.commits.messages);
const addTests = containsNewTests(source.diff.files) ? "X" : " ";
const codeApproved = pr.approvals > 0 ? "X" : " ";
const changes = Object.entries(commitTypes)
.map(([type, commits]) => formatCommitSection(type, commits))
.join("");
const changesWithoutLastBr = changes.slice(0, -1);
const userAdditions = extractUserAdditions(pr.description);
const result = `
<!--- user additions start --->
${userAdditions}
<!--- user additions end --->
**PR description below is managed by gitStream**
<!--- Auto-generated by gitStream--->
> #### Commits Summary
> This pull request includes the following changes:
${changesWithoutLastBr}
> #### Checklist
> - [${addTests}] Add tests
> - [${codeApproved}] Code Reviewed and approved
<!--- Auto-generated by gitStream end --->
`;
process.env[__filename] = result.split("\n").join("\n ");
return callback(null, process.env[__filename]);
}
module.exports = { filter: generateDescription, async: true };
gitStream CM Example: generateDescription
triggers:
exclude:
branch:
- r/dependabot/
automations:
generate_pr_desc:
if:
- true
run:
- action: update-description@v1
args:
description: |
{{ branch | generateDescription(pr, repo, source) }}
getCodeowners
Resolves the PR's code owners based on the repository's CODEOWNERS file
Returns: Array.<string> - user names
License: MIT
| Param | Type | Description |
|---|---|---|
| files | Array.<string> | the gitStream's files context variable |
| pr | Object | the gitStream's pr context variable |
| token | string | access token with repo:read scope, used to read the CODEOWNERS file |
Example
When used, create a secret TOKEN, and add it to the workflow file, in GitHub:
jobs:
gitStream:
...
env:
CODEOWNERS: ${{ secrets.GITSTREAM_CODEOWNERS }}
steps:
- name: Evaluate Rules
uses: linear-b/gitstream-github-action@v2
Plugin Code: getCodeowners
/**
* @module getCodeowners
* @description Resolves the PR's code owners based on the repository's CODEOWNERS file
* @param {string[]} files - the gitStream's files context variable
* @param {Object} pr - the gitStream's pr context variable
* @param {string} token - access token with repo:read scope, used to read the CODEOWNERS file
* @returns {string[]} user names
* @example {{ files | getCodeowners(pr, env.CODEOWNERS_TOKEN) }}
* @license MIT
**/
const { Octokit } = require("@octokit/rest");
const ignore = require('./ignore/index.js');
async function loadCodeownersFile(owner, repo, auth) {
const octokit = new Octokit({
request: { fetch },
auth,
});
const res = await octokit.repos.getContent({
owner,
repo,
path: 'CODEOWNERS'
});
return Buffer.from(res.data.content, 'base64').toString()
}
function codeownersMapping(data) {
return data
.toString()
.split('\n')
.filter(x => x && !x.startsWith('#'))
.map(x => x.split("#")[0])
.map(x => {
const line = x.trim();
const [path, ...owners] = line.split(/\s+/);
return {path, owners};
});
}
function resolveCodeowner(mapping, file) {
const match = mapping
.slice()
.reverse()
.find(x =>
ignore()
.add(x.path)
.ignores(file)
);
if (!match) return false;
return match.owners;
}
module.exports = {
async: true,
filter: async (files, pr, token, callback) => {
const fileData = await loadCodeownersFile(pr.author, pr.repo, token);
const mapping = codeownersMapping(fileData);
const resolved = files
.map(f => resolveCodeowner(mapping, f))
.flat()
.filter(i => typeof i === 'string')
.map(u => u.replace(/^@/, ""));
const unique = [...new Set(resolved)];
return callback(null, unique);
},
}
gitStream CM Example: getCodeowners
# -*- mode: yaml -*-
manifest:
version: 1.0
automations:
senior_review:
if:
- true
run:
- action: explain-code-experts@v1
args:
gt: 10
- action: add-reviewers@v1
args:
reviewers: {{ experts | intersection(list=owners) }}
experts: {{ repo | codeExperts(gt=10) }}
owners: {{ files | getCodeowners(pr, env.CODEOWNERS) }}
hasJiraIssue
Check to see if the input string matches a specified field for one or more Jira issues.
Returns: boolean - Returns true if the input string matches a Jira task title.
License: MIT
| Param | Type | Description |
|---|---|---|
| input | string | The string to search for a Jira task title. |
| password | string | Your Jira API token |
| key | string | The Jira key to search for matches against the input string. |
| jiraSpaceName | string | The name of the Jira space to search for tasks. |
string | The email address associated with the Jira API token. |
Example
{{ "https://github.com/{{ repo.owner }}/{{ repo.name }}/pull/{{ pr.number }}" | hasJiraIssue(password, key, jiraSpaceName, email) }}
Prerequisite Configuration
You will need to complete the following steps to use this plugin:
- Create an API token for your Jira account.
- Make the token available to gitStream via an environment variable.
Plugin Code: hasJiraIssue
/**
* @module hasJiraIssue
* @description Check to see if the input string matches a specified field for one or more Jira issues.
* @param {string} input - The string to search for a Jira task title.
* @param {string} password - Your Jira API token
* @param {string} key - The Jira key to search for matches against the input string.
* @param {string} jiraSpaceName - The name of the Jira space to search for tasks.
* @param {string} email - The email address associated with the Jira API token.
* @returns {boolean} Returns true if the input string matches a Jira task title.
* @example {{ "https://github.com/{{ repo.owner }}/{{ repo.name }}/pull/{{ pr.number }}" | hasJiraIssue(password, key, jiraSpaceName, email) }}
* @license MIT
*/
module.exports = {
async: true,
filter: async (inputString, password, key, jiraSpaceName, email, callback) => {
const jql = `"${key}" = "${inputString}"`;
const resp = await fetch(`https://${jiraSpaceName}.atlassian.net/rest/api/2/search`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Basic ' + btoa(`${email}:${password}`)
},
body: JSON.stringify({
'jql': jql,
'maxResults': 1,
"fieldsByKeys": true,
'fields': [ 'assignee' ]
})
});
const results = await resp.json();
return callback(null, !!results.issues?.length);
}
}
gitStream CM Example: hasJiraIssue
# -*- mode: yaml -*-
manifest:
version: 1.0
###### ** Configure This Section ** ######
# Configure this for your Jira instance and the email associated with your API key.
# You can safely use these values because only your API key is sensitive.
jiraSpaceName: "my-company" # e.g. my-company.atlassian.net
email: "my.email@example.com"
# If you're concerned about exposing this information,
# we recommend using environment variables for your production environment.
# -----------
# Pass the API token associated with the email above to gitStream via an environment variable.
jiraAuth: {{ env.JIRA_API_TOKEN }}
# Learn more about env: https://docs.gitstream.cm/context-variables/#env
# -----------
# Change this to the Jira field you want to match the input string against.
jiraField: "myField"
# If you want to search a custom field, you should provide the ID like so:
# jiraField: "cf[XXXXX]"
# Replace XXXXX with the ID of the custom field you want to search.
# More information:
# Using JQL to search the Jira API: https://support.atlassian.com/jira-service-management-cloud/docs/jql-fields/
# How to find the ID of a custom field: https://confluence.atlassian.com/jirakb/how-to-find-any-custom-field-s-ids-744522503.html
# -----------
prUrl: "https://github.com/{{ repo.owner }}/{{ repo.name }}/pull/{{ pr.number }}"
has_jira_issue: {{ prUrl | hasJiraIssue(jiraAuth, jiraField, jiraSpaceName, email) }}
automations:
has_jira_issue:
if:
- {{ not has_jira_issue }}
run:
- action: add-comment@v1
args:
comment: "This PR is missing a related issue in Jira. Please create a Jira task."
isFlaggedUser
Returns true if the username that is passed to this function is specified in a predefined list of users. This is useful if you want gitStream automations to run only for specified users.
Returns: boolean - Returns true if the user is specified in the flaggedUsers list, otherwise false.
License: MIT
| Param | Type | Description |
|---|---|---|
| Input | string | The GitHub username to check. |
Example
Plugin Code: isFlaggedUser
// Add users who you want to add to the flag list.
const flaggedUsers = ["user1", "user2"];
/**
* @module isFlaggedUser
* @description Returns true if the username that is passed to this function is specified in a predefined list of users.
* This is useful if you want gitStream automations to run only for specified users.
* @param {string} Input - The GitHub username to check.
* @returns {boolean} Returns true if the user is specified in the flaggedUsers list, otherwise false.
* @example {{ pr.author | isFlaggedUser }}
* @license MIT
*/
function isFlaggedUser(username) {
if (flaggedUsers.includes(username)) {
return true;
} else {
return false;
}
};
function containsString(arr, str) {
return arr.includes(str);
};
module.exports = isFlaggedUser;
gitStream CM Example: isFlaggedUser
# -*- mode: yaml -*-
manifest:
version: 1.0
automations:
detect_flagged_user:
if:
- {{ pr.author | isFlaggedUser }}
run:
- action: add-comment@v1
args:
comment: {{ pr.author }} is a gitStream user.
readMarkdownWithLinks
Reads a markdown file and follows internal links to create a comprehensive document view. Prevents circular references and supports configurable depth limits.
Returns: string - Combined content of the file and all linked files with headers, or structured object if structured option is true
License: MIT
| Param | Type | Default | Description |
|---|---|---|---|
| filePath | string | Path to the markdown file to read | |
| [options] | Object | {} | Configuration options for link following |
| [options.followLinks] | boolean | true | Whether to follow internal markdown links |
| [options.maxDepth] | number | 3 | Maximum depth to follow links to prevent excessive recursion |
| [options.structured] | boolean | false | Return structured data instead of combined text |
Example
Plugin Code: readMarkdownWithLinks
const fs = require('fs');
const path = require('path');
/**
* Safely read file with path traversal protection
* @param {string} filePath - Path to file to read
* @returns {string|null} File content or null if error/invalid path
*/
function readFile(filePath) {
// Whitelist: only allow relative paths within current directory
const normalizedPath = path.normalize(filePath);
if (path.isAbsolute(normalizedPath) || normalizedPath.includes('..')) {
console.log(`Invalid path: ${filePath}`);
return null;
}
try {
return fs.readFileSync(normalizedPath, 'utf8');
} catch (error) {
console.log(`Error reading file ${filePath}: ${error.message}`);
return null;
}
}
/**
* Extract internal markdown links from content
* Matches patterns like [text](./file.md) or [text](../file.md) or [text](file.md)
* @param {string} content - The markdown content to scan for links
* @param {string} basePath - Base directory path for resolving relative links
* @returns {Array} Array of link objects with text, path, and resolvedPath
*/
function extractInternalLinks(content, basePath) {
const linkRegex = /\[([^\]]+)\]\(([^)]+)\)/g;
const internalLinks = [];
let match;
while ((match = linkRegex.exec(content)) !== null) {
const linkText = match[1];
const linkPath = match[2];
// Check if it's an internal link (not http/https and ends with .md)
if (!linkPath.startsWith('http') && linkPath.endsWith('.md')) {
const resolvedPath = path.join(basePath, linkPath);
internalLinks.push({
text: linkText,
path: linkPath,
resolvedPath: resolvedPath
});
}
}
return internalLinks;
}
/**
* Read markdown file and follow internal links
* @param {string} filePath - Path to the markdown file
* @param {Object} options - Configuration options
* @param {boolean} options.followLinks - Whether to follow internal links (default: true)
* @param {number} options.maxDepth - Maximum depth to follow links (default: 3)
* @param {Set} options.visited - Internal set to track visited files (prevent cycles)
* @param {number} options.currentDepth - Current depth (internal)
* @returns {Object} Object containing content and linked files
*/
function readMarkdown(filePath, options = {}) {
const {
followLinks = true,
maxDepth = 3,
visited = new Set(),
currentDepth = 0
} = options;
const normalizedPath = path.normalize(filePath);
// Check if we've already visited this file (prevent cycles)
if (visited.has(normalizedPath)) {
return {
path: normalizedPath,
content: null,
error: 'Circular reference detected',
linkedFiles: []
};
}
// Check depth limit
if (currentDepth >= maxDepth) {
return {
path: normalizedPath,
content: readFile(normalizedPath),
error: null,
linkedFiles: [],
depthLimitReached: true
};
}
// Mark this file as visited
visited.add(normalizedPath);
// Read the main file content
const content = readFile(normalizedPath);
if (content === null) {
return {
path: normalizedPath,
content: null,
error: 'File not found or could not be read',
linkedFiles: []
};
}
const result = {
path: normalizedPath,
content: content,
error: null,
linkedFiles: []
};
// If we should follow links, extract and process them
if (followLinks) {
const basePath = path.dirname(normalizedPath);
const internalLinks = extractInternalLinks(content, basePath);
for (const link of internalLinks) {
const linkedFileResult = readMarkdown(link.resolvedPath, {
followLinks,
maxDepth,
visited: new Set(visited), // Create a new set for each branch
currentDepth: currentDepth + 1
});
result.linkedFiles.push({
linkText: link.text,
originalPath: link.path,
...linkedFileResult
});
}
}
return result;
}
/**
* @module readMarkdownWithLinks
* @description Reads a markdown file and follows internal links to create a comprehensive document view.
* Prevents circular references and supports configurable depth limits.
* @param {string} filePath - Path to the markdown file to read
* @param {Object} [options={}] - Configuration options for link following
* @param {boolean} [options.followLinks=true] - Whether to follow internal links
* @param {number} [options.maxDepth=3] - Maximum depth to follow links
* @param {boolean} [options.structured=false] - Return structured data instead of combined text
* @returns {string} Combined content of the file and all linked files with headers
* @example {{ "docs/README.md" | readMarkdownWithLinks }}
* @example {{ "docs/README.md" | readMarkdownWithLinks(maxDepth=2) }}
* @license MIT
*/
function readMarkdownWithLinks(filePath, options = {}) {
const {
followLinks = true,
maxDepth = 3,
structured = false
} = options;
const result = readMarkdown(filePath, {
followLinks,
maxDepth,
visited: new Set(),
currentDepth: 0
});
// Return structured data if requested
if (structured) {
return result;
}
// Otherwise return combined content
function combineContent(fileResult, depth = 0) {
const indent = ' '.repeat(depth);
let combined = '';
if (fileResult.content) {
combined += `${indent}=== ${path.basename(fileResult.path)} ===\n`;
combined += fileResult.content + '\n\n';
}
if (fileResult.linkedFiles) {
for (const linkedFile of fileResult.linkedFiles) {
combined += combineContent(linkedFile, depth + 1);
}
}
return combined;
}
return combineContent(result);
}
module.exports = readMarkdownWithLinks;
// ============================================================================
// TESTS (for local development only)
// ============================================================================
if (require.main === module) {
const fs = require('fs');
function assert(condition, message) {
if (!condition) { console.error(`❌ ${message}`); process.exit(1); }
console.log(`✅ ${message}`);
}
// Setup
fs.mkdirSync('./test-files/sub', { recursive: true });
fs.writeFileSync('./test-files/main.md', '# Main\n[Related](./related.md)\n[Another](./another.md)\n[External](https://example.com)');
fs.writeFileSync('./test-files/related.md', '# Related\n[Sub](./sub/subdoc.md)');
fs.writeFileSync('./test-files/another.md', '# Another');
fs.writeFileSync('./test-files/sub/subdoc.md', '# Sub\n[Main](../main.md)');
console.log('🧪 Running tests\n');
// Test 1: Basic reading
let r = readMarkdown('./test-files/main.md', { followLinks: false });
assert(r.content?.includes('# Main'), 'Basic file reading');
// Test 2: Link following
r = readMarkdown('./test-files/main.md', { maxDepth: 2 });
console.log(r.linkedFiles[0])
assert(r.linkedFiles.length === 2, 'Follows 2 links');
assert(r.linkedFiles[0].linkedFiles.length === 1, 'Nested link following');
// Test 3: Circular reference
r = readMarkdown('./test-files/main.md', { maxDepth: 5 });
const circularRef = r.linkedFiles[0].linkedFiles[0].linkedFiles[0];
assert(circularRef?.error === 'Circular reference detected', 'Circular reference detection');
// Test 4: Depth limit
r = readMarkdown('./test-files/main.md', { maxDepth: 1 });
assert(r.linkedFiles[0].linkedFiles.length === 0, 'Depth limit respected');
// Test 5: Non-existent file
r = readMarkdown('./test-files/missing.md');
assert(r.error === 'File not found or could not be read', 'Non-existent file handling');
// Test 6: Combined output
const combined = readMarkdownWithLinks('./test-files/main.md', { maxDepth: 1 });
assert(combined.includes('=== main.md ==='), 'Combined format includes headers');
assert(combined.includes(' === related.md ==='), 'Nested files indented');
// Test 7: Path traversal blocked
r = readMarkdown('../../../etc/passwd');
assert(r.content === null, 'Path traversal blocked');
assert(r.error === 'File not found or could not be read', 'Path traversal returns error');
// Test 8: Absolute path blocked
const content1 = readFile('/etc/passwd');
assert(content1 === null, 'Absolute Unix path blocked');
const content2 = readFile('C:\\Windows\\System32\\config');
assert(content2 === null, 'Absolute Windows path blocked');
// Test 9: Empty file handling
fs.writeFileSync('./test-files/empty.md', '');
r = readMarkdown('./test-files/empty.md');
assert(r.content === '', 'Empty file handled');
assert(r.linkedFiles.length === 0, 'Empty file has no links');
console.log('\n🎉 All tests passed!');
fs.rmSync('./test-files', { recursive: true });
}
gitStream CM Example: readMarkdownWithLinks
# -*- mode: yaml -*-
# Example gitStream configuration using readMarkdownWithLinks for LinearB AI code reviews
# This shows how to enhance AI code reviews with comprehensive documentation context
manifest:
version: 1.0
automations:
# Enhanced AI code review with comprehensive documentation context
ai_review_with_full_docs:
if:
- {{ not pr.draft }}
- {{ pr.files | match(regex=r".*\.(js|ts|py|go|java|cpp|cs)") | some }}
run:
- action: code-review@v1
args:
guidelines: |
Code Review Guidelines:
{{ "REVIEW_RULES.md" | readMarkdownWithLinks | dump }}
Project Documentation Context:
{{ "README.md" | readMarkdownWithLinks(maxDepth=2) | dump }}
Architecture and Design:
{{ "docs/ARCHITECTURE.md" | readMarkdownWithLinks(maxDepth=1) | dump }}
# Context-aware reviews based on changed file areas
contextual_ai_review:
if:
- {{ not pr.draft }}
run:
- action: code-review@v1
args:
guidelines: |
Base Review Guidelines:
{{ "REVIEW_RULES.md" | readMarkdownWithLinks | dump }}
{% if pr.files | match(regex=r"src/api/.*") | some %}
API-Specific Guidelines and Documentation:
{{ "docs/api/README.md" | readMarkdownWithLinks | dump }}
{% endif %}
{% if pr.files | match(regex=r".*test.*") | some %}
Testing Standards and Guidelines:
{{ "docs/testing/README.md" | readMarkdownWithLinks | dump }}
{% endif %}
{% if pr.files | match(regex=r".*security.*") | some %}
Security Guidelines:
{{ "docs/security/GUIDELINES.md" | readMarkdownWithLinks | dump }}
{% endif %}
# Large PR reviews with extensive context
comprehensive_review_large_prs:
if:
- {{ not pr.draft }}
- {{ pr.files | length > 10 }} # Large changes
run:
- action: code-review@v1
args:
guidelines: |
Comprehensive Review Guidelines for Large Changes:
{{ "REVIEW_RULES.md" | readMarkdownWithLinks | dump }}
Full Project Context:
{{ "README.md" | readMarkdownWithLinks(maxDepth=1) | dump }}
Contributing Guidelines:
{{ "CONTRIBUTING.md" | readMarkdownWithLinks | dump }}
Architecture Documentation:
{{ "docs/ARCHITECTURE.md" | readMarkdownWithLinks(maxDepth=2) | dump }}